Este título tan raro y que probablemente no diga nada a personas que no están familiarizadas con la informática médica es la clave para avanzar en un estándar abierto que permita crear la independencia necesaria entre los sistemas sanitarios y los grandes proveedores de software médico.
Actualmente el negocio sanitario es un caramelo que nadie quiere dejar escapar; IBM, Microsoft y las grandes corporaciones han creado recientemente divisiones específicas para dar servicio a los sistemas de salud, está claro que el negocio es suculento y que detrás está el gobierno que garantiza grandes beneficios.

El software privativo que ofrecen las grandes empresas está acompañado de toda una serie de certificaciones indicativas de que cumplen con todos los estándares del mercado, pero en realidad es que cuando firmas el primer contrato estás condenado de por vida a depender de ese proveedor más aún cuando se trata de un sistema sanitario donde hay miles de profesiones y millones de pacientes alimentando el sistema cada día.
El problema actual del software médico es que los estándares definen sobre todo interfaces, es verdad que si un software cumple con la especificación de HL7 RIM v3 está garantizando que ese sistema puede intercambiar información con otro que cumple esa misma especificación, pero eso de ninguna forma nos garantiza que los datos que contiene el sistema estén en un formato estándar que permita ser procesados por otro software de otro proveedor, con lo cual se hace prácticamente imposible que el hospital pueda cambiar de software si en un momento dado el proveedor actual no nos conviene o si otro proveedor ofrece un software más moderno, más funcional o simplemente más barato.
Todo esto se resume en lo siguiente; los sistemas transaccionales actuales donde se exigen un gran número de operaciones por segundo requieren de un software que está estrechamente ligado a las bases de datos es decir, el conocimiento clínico está impreso en el código fuente y éste está totalmente acoplado a los datos que normalmente se encuentran en bases de datos relacionales, con este paradigma la única forma de migrar toda esta información y conocimiento a otro sistema es mediante la creación de programas conversores que requieren colaboración estrecha entre los programadores del proveedor actual y los del nuevo proveedor, ya os podéis imaginar la cara que pondría Microsoft si su cliente que le está pagando cientos de millones de euros anuales le dice, «Mira que ya no necesito más tus servicios, que voy a migrar a otra plataforma, por favor dame el código fuente de tu software y explícame para que sirven cada uno de los campos del esquema de tu base de datos que lo vamos a convertir todo al nuevo sistema» esto sin contar los costes y el tiempo que requiere hacer esta migración.
Buenos y ustedes preguntarán ¿ esto se puede hacer de otra forma ? y yo respondo ¡ pues sí ! para eso tenemos el modelo dual que se define en el estándar openEHR, un poco más abajo voy a entrar en detalles más técnicos acerca del modelo pero en resumen y buscando un símil que obvia muchos aspectos, el modelo dual sería como un puzle donde en una caja están todas las piezas necesarias para construir cualquier HCE y una serie de reglas que dicen como se deben combinar dichas piezas, los médicos usando las piezas y las reglas crean sus registros médicos y por otro lado está el software que interpreta ese puzle y lo automatiza en una computadora. Otro símil aunque este es un poco más vasto que el anterior sería el siguiente; tenemos una especificación para construir hojas de cálculo mediante casillas y operaciones entre dichas casillas y los expertos en la materia crean combinaciones de casillas y operaciones para producir plantillas para realizar cálculos como por ejemplo la amortización de un préstamo y luego hay distintos proveedores de software que son capaces de recoger los datos de esas plantillas y presentarlas de forma amigable y almacenarlas creando instancias de las plantillas combinadas con los datos.
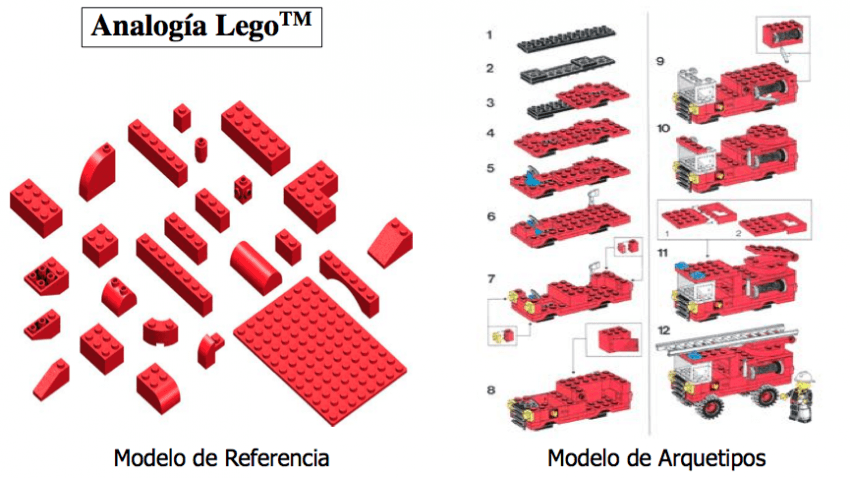
Empleando un lenguaje más técnico y formal OpenEHR define un modelo de referencia para la representación de la información clínica así como un modelo de arquetipos encargado de representar conceptos clínicos de mayor nivel semántico.
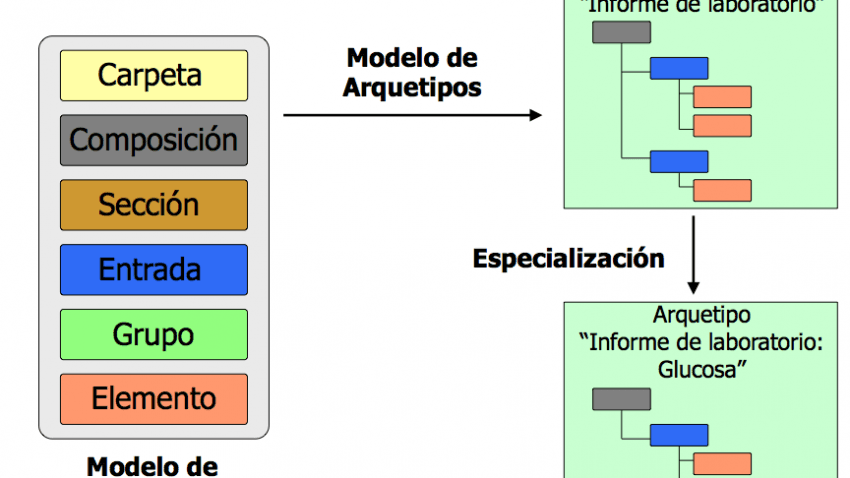
En el modelo de referencia se incluyen todas las clases necesarias para representar cualquier tipo de información clínica incluyendo información de contexto relativa a esos datos, como puede ser el médico responsable (participantes), las fechas de realización de las pruebas, protocolo o el lugar del acto clínico. Es un modelo simple y flexible adaptable a cualquier estructura de información sanitaria. En cuanto al modelo de arquetipos, permite definir de manera formal conceptos clínicos de mayor nivel semántico, como puede ser un informe de alta, una prueba de laboratorio o la administración de sustancias y para ello se basa en las clases del modelo de referencia, restringíendolas a unos valores o estructuras de datos precisas.
Todos los nodos representados en el arquetipo pueden enlazarse con terminologías clínicas que doten a la definición del arquetipo de un significado preciso que asegure su interoperabilidad semántica.
OpenEHR dispone de una herramienta para la gestión del conocimiento clínico, con esta herramienta se puede compartir conocimiento (arquetipos) y controlar su cliclo de vida, así como abrir nuevos proyectos donde colaboren distintas personas en la creación y gestión del conocimiento clínico.
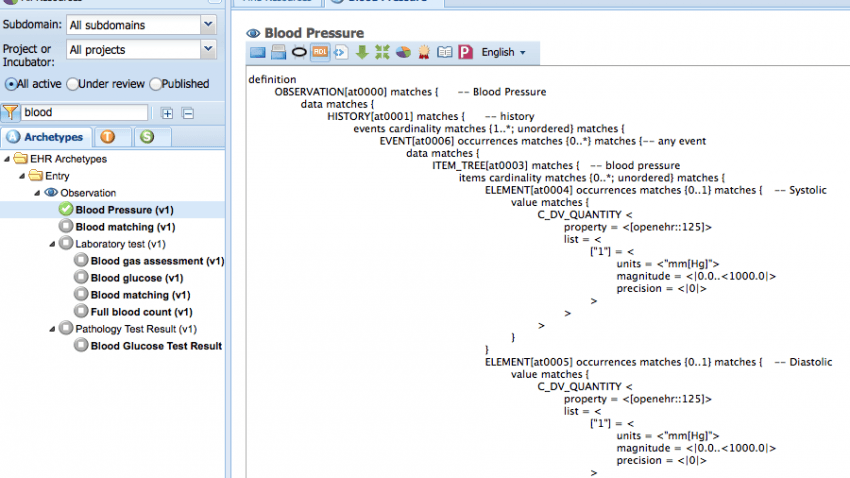
OpenEHR tiene como característica que el conocimiento representado mediante los arquetipos puede ser traducido a cualquier idioma, para ello dispone de una ontología propia multilenguaje que a su vez se puede alinear con cualquier otra ontología médica externa.
El concepto de separar la información del conocimiento es lo que en openEHR se llama modelo dual, este enfoque viene a justificar en un entorno sanitario que un médico sabe organizar y gestionar la información que maneja y un ingeniero en informática sabe como automatizar procesos, recoger la información con una interfaz agradable y almacenar grandes volúmenes de datos.
Uno de los autores de openEHR Thomas Beale, durante su trabajo en el grupo GEHR observaba reiteradamente que en los procesos de definición e implementación de los sistemas informáticos para la gestión de registros médicos, se producían discrepancias entre médicos e ingenieros y no había una línea divisoria clara entre el trabajo de cada uno y por ese motivo, Thomas quiso buscar la forma de independizar ambos procesos: Por un lado la definición del conocimiento y por otro el procesado de dicho conocimiento en un sistema informático. A esta separación la llamó modelo dual.
Tenemos que considerar que la complejidad de la información sanitaria, su heterogeneidad en cuanto a los tipos de datos representados y la continua variabilidad del conocimiento médico, hace que los sistemas de información se suelan quedar obsoletos y sean difíciles de mantener.
El modelo dual tiene como base fundamental separar la información del conocimiento teniendo en cuenta que, la información son aquellos datos que una vez almacenados en el sistema no varían con el tiempo, en el contexto sanitario corresponde a los datos introducidos respecto a la salud de un paciente, un ejemplo sería la medida de la presión sanguínea de un paciente 130/80 mm[Hg] en una fecha concreta. En cuanto al conocimiento, se refiere al conjunto de conceptos de un determinado dominio profesional, conceptos que pueden variar o modificarse con el paso del tiempo y cuyo significado completo sólo conocen los profesionales expertos en ese campo, en línea con el ejemplo anterior, se puede considerar como conocimiento el concepto “presión sanguínea” que está compuesta de presión sistólica (medida de presión cuando el corazón se encuentra contraido), presión diastólica (medida de presión cuando el corazón está relajado), unidad de medida mm[Hg]. Este conocimiento médico en un momento dado, puede llegar a variar por razones estrictamente médicas, como por ejemplo: Recoger la media de pulsaciones del corazón durante la medida, o medir la temperatura corporal, por que a posteriori se determina que son importantes a la hora de medir la presión arterial. Por este motivo podemos decir que los datos no varían pero el conocimiento si.
Esto que os cuento en esta entrada es sólo el principio, se han introducido conceptos como los de ontología y semántica, estos conceptos están relacionados con el futuro de la medicina, en los próximos años se va a producir una revolución en la medicina con la incorporación de la inteligencia artificial, la IA va a mejorar sustancialmente los diagnósticos médicos, ya hay estudios donde se asegura que las máquinas son capaces en determinados contextos de; cometer menos errores diagnosticando enfermedades que los médicos, la medicina basada en evidencias va a permitir que las máquinas analicen los datos y emitan diagnósticos de manera precisa y para todo esto es necesario incorporar estándares que permitan a las máquinas entender o interpretar los datos que contienen las HCE.